给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
致谢:
特别感谢 @pbrother 添加此问题并且创建所有测试用例。
示例 1:
输入:s = "abc", t = "ahbgdc" 输出:true
示例 2:
输入:s = "axc", t = "ahbgdc" 输出:false
思路:
dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。
- f (s[i – 1] == t[j – 1])
- t中找到了一个字符在s中也出现了
- if (s[i – 1] != t[j – 1])
- 相当于t要删除元素,继续匹配
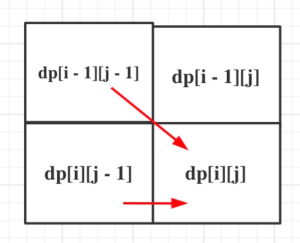
if (s[i – 1] == t[j – 1]),那么dp[i][j] = dp[i – 1][j – 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1
if (s[i – 1] != t[j – 1]),此时相当于t要删除元素,t如果把当前元素t[j – 1]删除,那么dp[i][j] 的数值就是 看s[i – 1]与 t[j – 2]的比较结果了,即:dp[i][j] = dp[i][j – 1];
从递推公式可以看出dp[i][j]都是依赖于dp[i – 1][j – 1] 和 dp[i][j – 1],所以dp[0][0]和dp[i][0]是一定要初始化的。
代码如下:
class Solution {
public:
bool isSubsequence(string s, string t) {
vector<vector<int>> dp(t.size() + 1, vector<int>(s.size() + 1, 0));
for (int i = 1; i <= t.size(); i++) {
for (int j = 1; j <= s.size(); j++) {
if (s[j - 1] == t[i - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
if (dp[t.size()][s.size()] == s.size()) {
return true;
} else
return false;
}
};
给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 + 7 取模。
示例 1:
输入:s = "rabbbit", t = "rabbit"输出:3解释: 如下所示, 有 3 种可以从 s 中得到"rabbit" 的方案。rabbbitrabbbitrabbbit
示例 2:
输入:s = "babgbag", t = "bag"输出:5解释: 如下所示, 有 5 种可以从 s 中得到"bag" 的方案。babgbagbabgbagbabgbagbabgbagbabgbag
思路:
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
两种情况
- s[i – 1] 与 t[j – 1]相等
- s[i – 1] 与 t[j – 1] 不相等
当s[i – 1] 与 t[j – 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i – 1]来匹配,那么个数为dp[i – 1][j – 1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要 dp[i-1][j-1]。
一部分是不用s[i – 1]来匹配,个数为dp[i – 1][j]。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i – 1] 与 t[j – 1]相等时,dp[i][j] = dp[i – 1][j – 1] + dp[i – 1][j];
当s[i – 1] 与 t[j – 1]不相等时,dp[i][j]只有一部分组成,不用s[i – 1]来匹配(就是模拟在s中删除这个元素),即:dp[i – 1][j]
所以递推公式为:dp[i][j] = dp[i – 1][j];
初始化:
从递推公式dp[i][j] = dp[i – 1][j – 1] + dp[i – 1][j]; 和 dp[i][j] = dp[i – 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,所以 dp[i][0] 和dp[0][j]是一定要初始化的。
代码如下:
class Solution {
public:
int numDistinct(string s, string t) {
vector<vector<uint64_t>> dp(s.size() + 1,
vector<uint64_t>(t.size() + 1, 0));
for (int i = 0; i < s.size(); i++) {
dp[i][0] = 1;
}
for (int i = 1; i < t.size(); i++) {
dp[0][i] = 0;
}
for (int i = 1; i <= s.size(); i++) {
for (int j = 1; j <= t.size(); j++) {
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else
dp[i][j] = dp[i - 1][j];
}
}
return dp[s.size()][t.size()];
}
};
给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。
每步 可以删除任意一个字符串中的一个字符。
示例 1:
输入: word1 = "sea", word2 = "eat" 输出: 2 解释: 第一步将 "sea" 变为 "ea" ,第二步将 "eat "变为 "ea"
示例 2:
输入:word1 = "leetcode", word2 = "etco" 输出:4
思路:
dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word2,想要达到相等,所需要删除元素的最少次数。
- 当word1[i – 1] 与 word2[j – 1]相同的时候
- 当word1[i – 1] 与 word2[j – 1]不相同的时候
当word1[i – 1] 与 word2[j – 1]相同的时候,dp[i][j] = dp[i – 1][j – 1];
当word1[i – 1] 与 word2[j – 1]不相同的时候,有三种情况:
情况一:删word1[i – 1],最少操作次数为dp[i – 1][j] + 1
情况二:删word2[j – 1],最少操作次数为dp[i][j – 1] + 1
情况三:同时删word1[i – 1]和word2[j – 1],操作的最少次数为dp[i – 1][j – 1] + 2
那最后当然是取最小值,所以当word1[i – 1] 与 word2[j – 1]不相同的时候,递推公式:dp[i][j] = min({dp[i – 1][j – 1] + 2, dp[i – 1][j] + 1, dp[i][j – 1] + 1});
因为 dp[i][j – 1] + 1 = dp[i – 1][j – 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i – 1][j] + 1, dp[i][j – 1] + 1);
从递推公式中,可以看出来,dp[i][0] 和 dp[0][j]是一定要初始化的。
代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++)
dp[i][0] = i;
for (int i = 0; i <= word2.size(); i++)
dp[0][i] = i;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
}
return dp[word1.size()][word2.size()];
}
};
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros" 输出:3 解释: horse -> rorse (将 'h' 替换为 'r') rorse -> rose (删除 'r') rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution" 输出:5 解释: intention -> inention (删除 't') inention -> enention (将 'i' 替换为 'e') enention -> exention (将 'n' 替换为 'x') exention -> exection (将 'n' 替换为 'c') exection -> execution (插入 'u')
思路:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]。
if (word1[i - 1] == word2[j - 1]) 不操作 if (word1[i - 1] != word2[j - 1]) 增 删 换
由于增删换都对应操作数加一,所以可以合在一起。
初始化:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i; for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1,
vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) {
dp[i][0] = i;
}
for (int i = 0; i <= word2.size(); i++) {
dp[0][i] = i;
}
if (word1 == word2)
return 0;
if (word1.size() == 0 && word2.size() != 0) {
return word2.size();
}
if (word2.size() == 0 && word1.size() != 0) {
return word1.size();
}
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] =
min({dp[i - 1][j - 1], dp[i][j - 1], dp[i - 1][j]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};



暂无评论